Motivation. Autoencoders have the problem of unstructured latent space, i.e. when sampling purely randomly in the latent space and decoding it to , the generated data is not very good—there are only a few ‘locations’ in the latent space that represents realistic data.
To solve this, we must ‘structure’ the latent space such that sampling it would almost always give real data. The simplest idea would be to force the latent space to be a standard normal distribution.

def. Variational Autoencoder (VAE).12 Let a probability distribution of data and latent distribution of .
- The encoder encodes the data into variables . This forms the conditional latent distribution, .
- Note that the latent representation is not a vector like autoencoders, but instead a full probability distribution
- The decoder then takes a sampled latent point , and decodes it into the datapoint to get a distribution for the data .
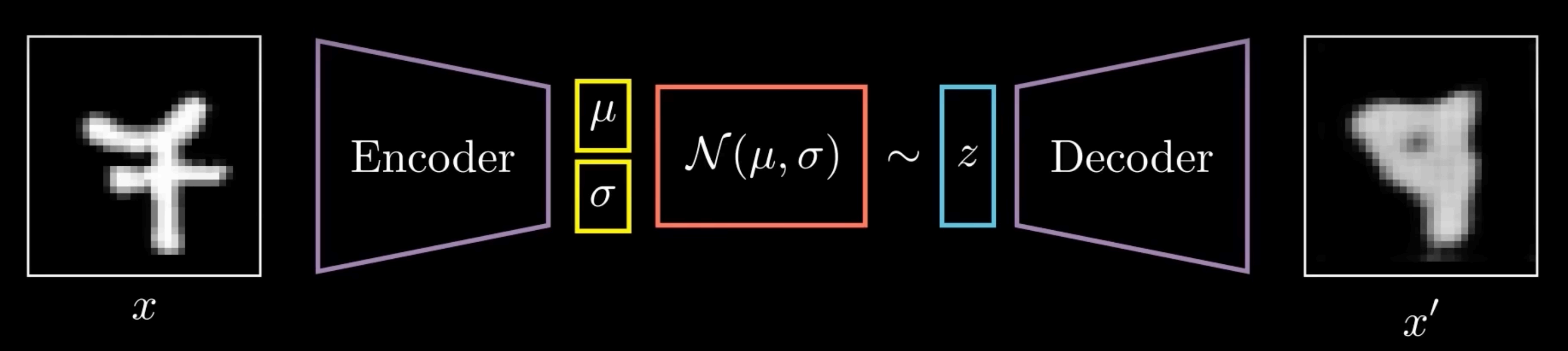 Objective. The loss, also known as Evidence Lower Bound (ELBO) can be shown to be as follows:
Objective. The loss, also known as Evidence Lower Bound (ELBO) can be shown to be as follows:
where the terms: 3. Expectation term is equivalent to the L2 Norm between the original image and the reconstruction 4. KL-divergence term is simply to make sure that resembles a standard normal distribution.