Motivation. While gradient descent is accurate it is computationally intensive. We shall consider heuristics to improve the computational speed.
def. Gradient Descent. We will use the following notation/characterization of gradient descent.
where
- are learning rates on step
- is the loss function for datapoint and weghts
Motivaiton. The first step to optimize is to avoid calculating the gradients of all datapoints .
def. Stochastic Gradient Descent. For each step, we instead randomly choose one datapoint, to update:
This works because
Motivation. This is better, but this leads to lots of steps . We can group or “batch” data together to reduce that, while also not calculating all gradients like classical GD. The gradient used like this, is an unbaised Estimator of the true gradient calculated over all datapoints.
def. Batch Gradient Descent. For each step, choose a random batch of size , and average them.
Momentum
Intuition. Momentum is a way to “dampen” the oscillations when taking many tiny steps, and to reduce the number of steps required for convergence (by a factor of a square root). This dampening, implemented for stochastic/batch gradient descent, can be considered as a bias-variance-tradeoff of the gradient estimator.
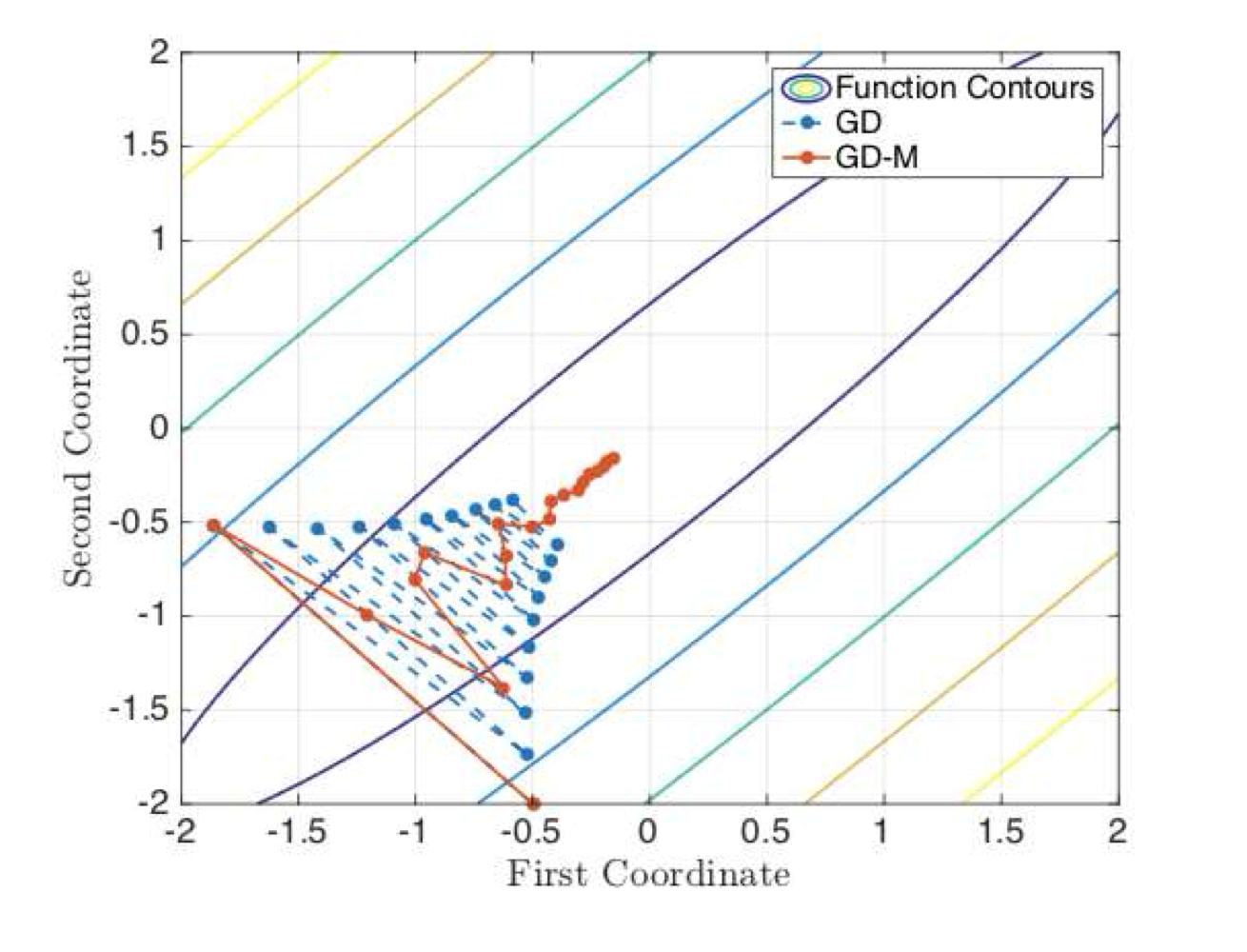
alg. Nesterov’s Accelerated Gradient Descent (NAG). This is convoluted but it’s optimized to guarantee a certain rate of convergence, see below. This is also the original implementation of momentum.
- let
- let
- for steps , setting :
- Momentum:
- Descent:
thm. (informal statement). Step will minimize:
i.e., the distance to optimal drops quadratically wrt
alg. GD with Momentum. A more intuitive way to incorporate momentum. Setting to how much you want to accumulate prior momentum:
- for :
- Momentum:
- Descent:
Higher-order Methods
Intuition. Curvature is useful for gradient descent.
Adaptive Learning Rates
Intuition. We adapt the learning rates for each parameter. Small learning rate for frequently updated parameters, and large learning rates for infrequently updated parameters. This works because:
- Frequently updated parameters can be overfit, and infrequently updated ones underfit
- By adjusting learning rates inversly to frequency/magnitude of update we reduce overand underfitting, while also improving convergence rates
alg. GD with Adaptive Learning Rates. (Adagrad) It is proven that it reduces regret bounds
- for
- Sum-of-Squares accumulation:
- Adaptive rate: (element-wise divide)
- Descent: The sum of squares will grow fast for parameters with high gradients and/or frequent updates. The learning rate is the reciprocal, and thus diminishes. v.v.
alg. Root-Mean-Squared Propagation. (RMSprop). Adaptive learning rates using exponential moving average. Set a learning rate sequance such that at a rate . Then:
- for
- Sum-of-Squares accumulation:
- Decaying SoS (=“preconditioner”) (element-wise divide)
- Descent:
Adaptive Learning Rate + Momentum
alg. Adaptive Learning Rate with Momentum (ADAM). Integrate both the adaptive learning rate (into second moment) and momentum (first moment).
- for
- First moment:
- Debias:
- First moment:
- Debias:
- Descent:
- First moment:
Conclusion
Just use ADAM.