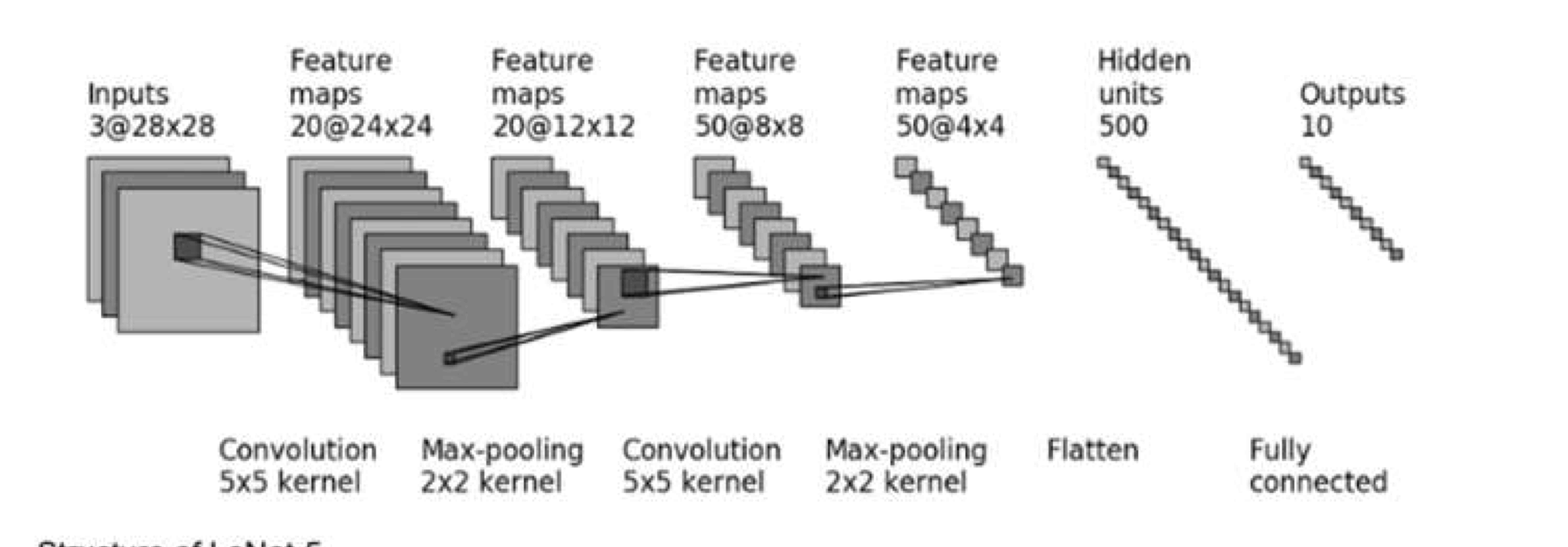
Intuition. We aim to take advantage of the features of human vision to inspire the architection of computer vision model. Notably human vision has:
- Local connectivity, i.e. near things are related
- Invariant in many transformation, i.e. rotating, stretching, flipping objects doesn’t make them different objects
- the RGB channels of an image are not natural, it’s for human eyes only.
Components
Convolution Layer
Intuition. The term comes from a function convolution, where two functions are “combined.” 3b1b from 4:45 shows taking a moving average of a function , which is a type of convolution. The moving average (function ) filters the original function . This is denoted as .
In computer vision, we only consider discrete convolution, which is also called a kernel. How Blurs & Filters Work - Computerphile - YouTube visualizes the convolution well. Also see: 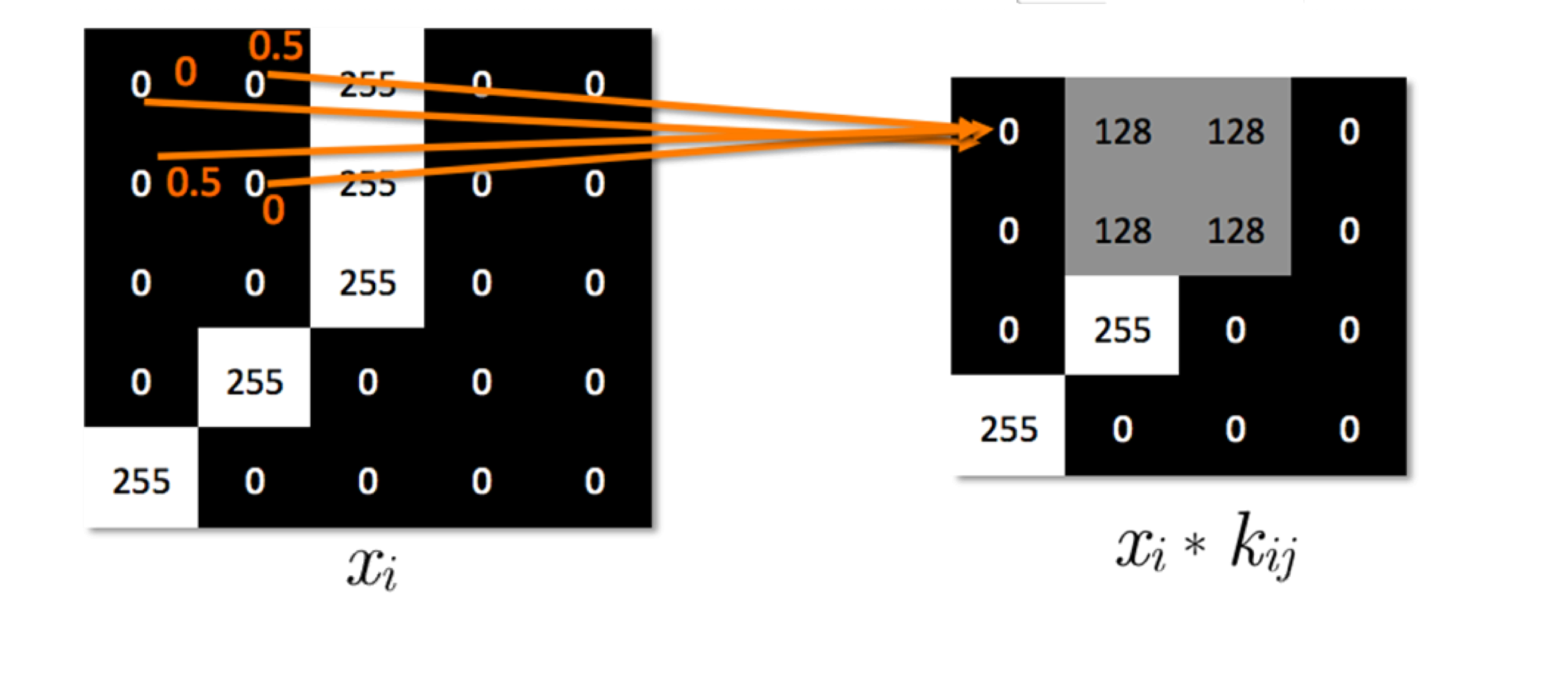 where the left is the original “image” and the right is the filtered image. is the kernel applied that results in cell in the output. If you don’t want the image to get to smaller, you can also zero-pad the image’s border:
where the left is the original “image” and the right is the filtered image. is the kernel applied that results in cell in the output. If you don’t want the image to get to smaller, you can also zero-pad the image’s border:
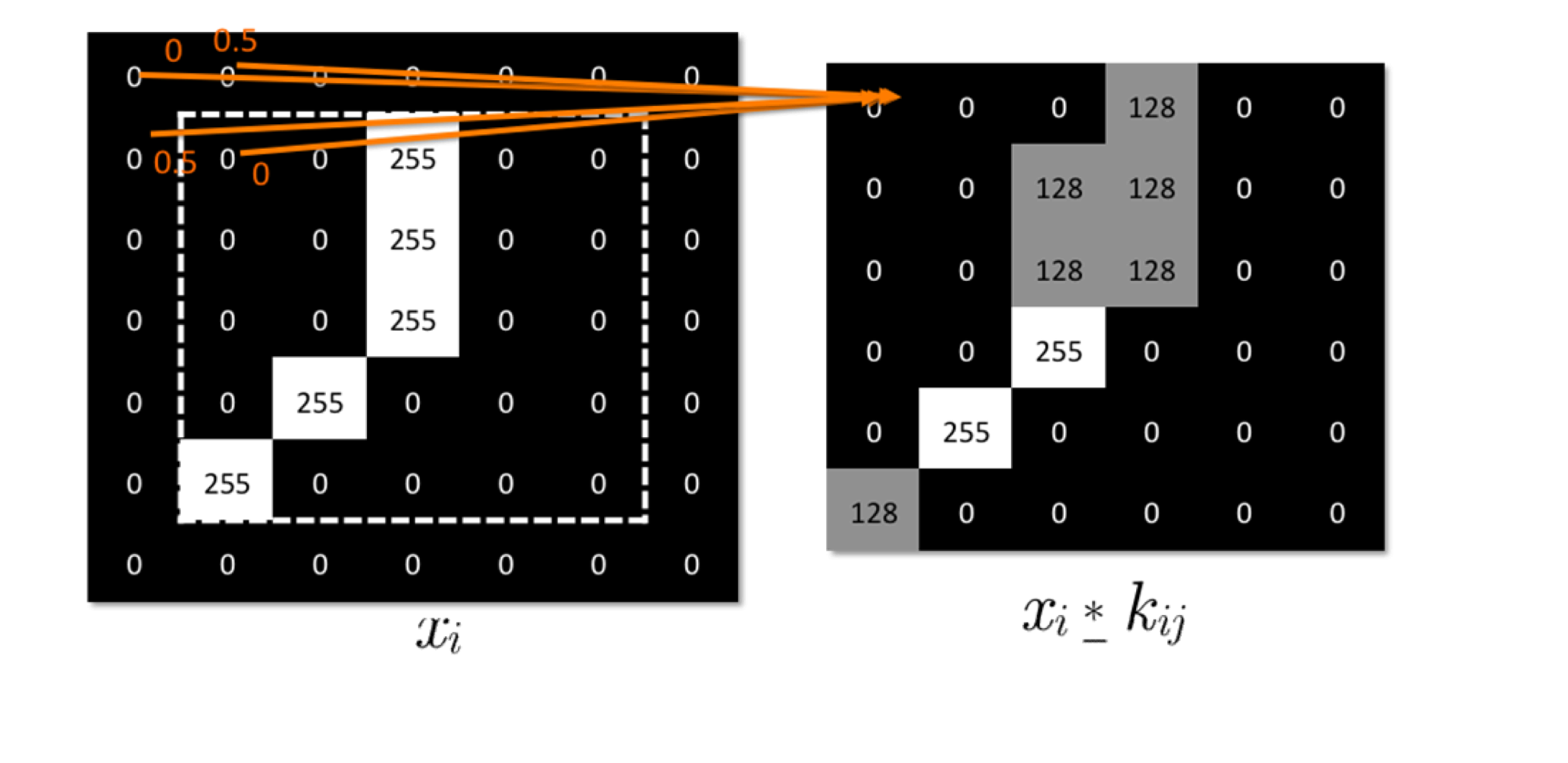
Pooling Layer
Pooling layers don’t have special parameters. They are just a simple kernel that takes either the maximum or the average of the input: 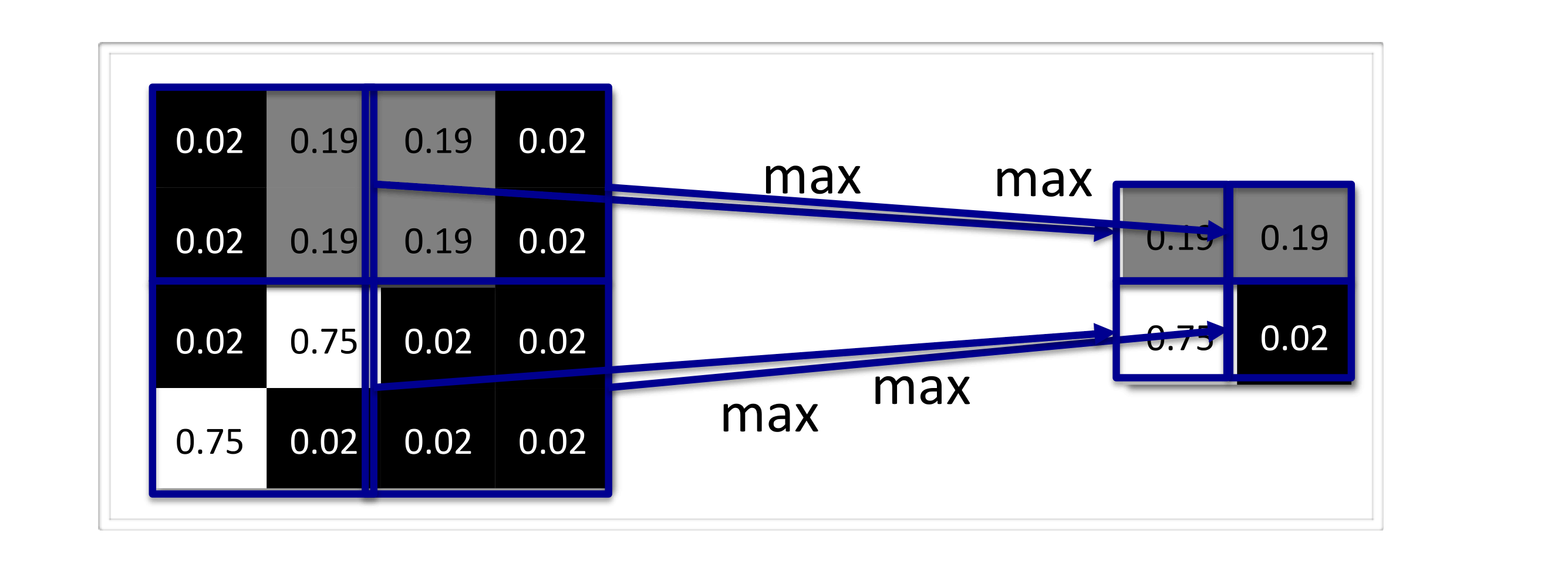 Normally, CNNs alternate between convolutional and pooling layers.
Normally, CNNs alternate between convolutional and pooling layers.