def. GPT-2 is OpenAI’s first public Large Language Model
Note
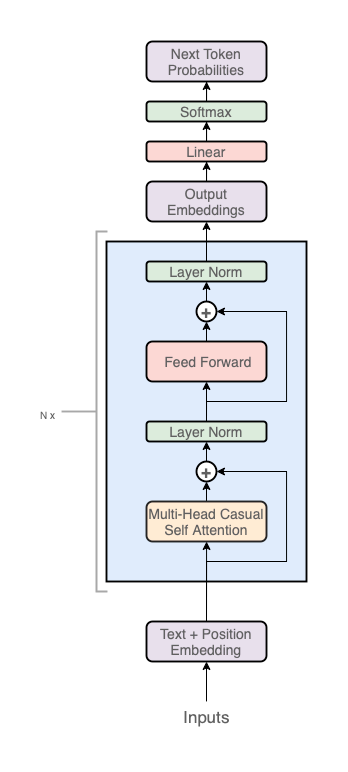
Parameters
Hyperparameters
- Context Length: number of tokens allowed in input
- Sequence length < Context Length. Sequence is the actual length of text input
- Vocabulary Size: the tokenizer’s size of vocabulary
- Embedding Dimension: the number of dimensions in the word embedding
- Head Count: number of attention heads in each attention layer
Learnable Parameters
wte(Vocab Size → Embedding Dimension): lookup table from token to embeddingwpe(Context Length → Embedding Dimension): lookup table for positional embedding- in the Normalization layer
w,b(N → N), (N): Weights and biases in the linear (=linear) layers- Attention
- Query, Key, and Value matricies, each (Sequence Length → Embed. Dim.):
Word Embeddings
- Given a string of text, a tokenizer will split this text into chunks (tokens)
- Learnable embedding matrix
wteandwpeencodes this into an embedding These vectors , embedded in the embedding space will:
- Be similar in meaning if cosine similarity is larger
- Difference in vectors i.e. the direction embed meaning that is the “difference in meaning” between and
Attention
- Each token in string is multiplied with a Query matrix
- The resulting vector encodes the question, e.g. “are there adjectives in front of me?”
- The resulting vector
- Each token in string is multiplied with a Key matrix
- The resulting vector encodes the answer, e.g. “I’m an adjective!”
- The cosine similarity of a query-key pair encodes “how well the question is answered”
- each column of the result passes thru a Softmax and Sigmoid function