Motivation. In the input space, draw a line to classify into two categories. This is achievable using linear regression
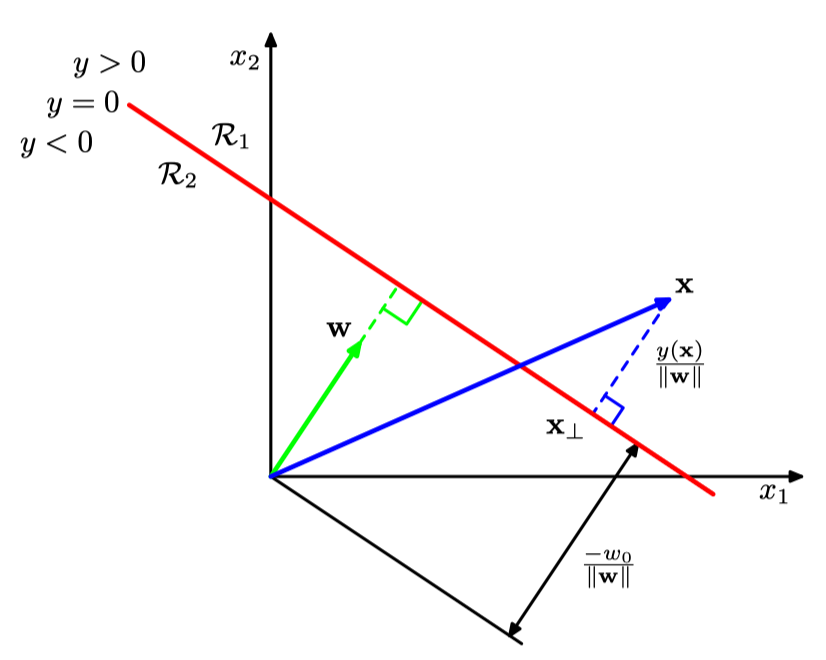
Discriminant Function
def. Discriminant Function takes an input vector and assigns into one of classes, .
- def. Decision Surface is the boundary that splits the classes in input space.
- def. Decision Region is the regions generated by the decision surfaces that correspond to a single class. When there is two classes, then:
And assign:
- is orthogonal to the decision surface hyperplane (via linalg; green in image)
- determines the distace from the origin of the decision surface
 When there are classes then we cant just split into regions naively because:
When there are classes then we cant just split into regions naively because:
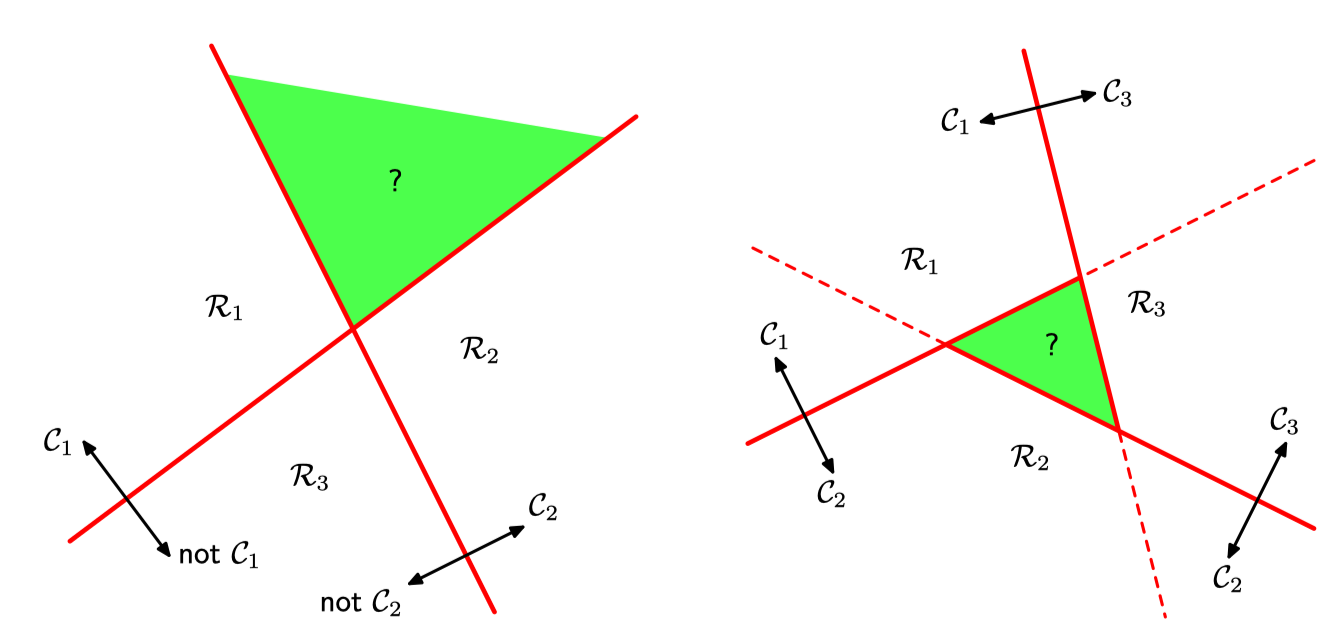 Therefore we instead introduce a discriminant function for every pair of classes, in total DFs for each :
Therefore we instead introduce a discriminant function for every pair of classes, in total DFs for each :
and then assign to: i.e. the maximum of all discriminant functions. The pairwise decision surface for pair is:
thm. Such decision regions are singly connected and convex.1
Linear Discriminnant Models
def. Perceptron Algorithm. (only works for , but is illustrative.)
where:
- a fixed (=non-trained) function . Includes bias component.
- an activation function where:
Optimizing the Perceptron Algorithm
def. Perceptron Error Function.
where
- Sums over , all the misclassified ’s
- indicates which class it is in, . Intuition. In this error function:
- Correct classification has error
- Incorrect classification has error Optimizing this globally using is too computationally intensive. We instead use:
- is simply the learning step index
- is the learning rate. Adjustable
Visualization. Following are two steps of a perceptron optimization.
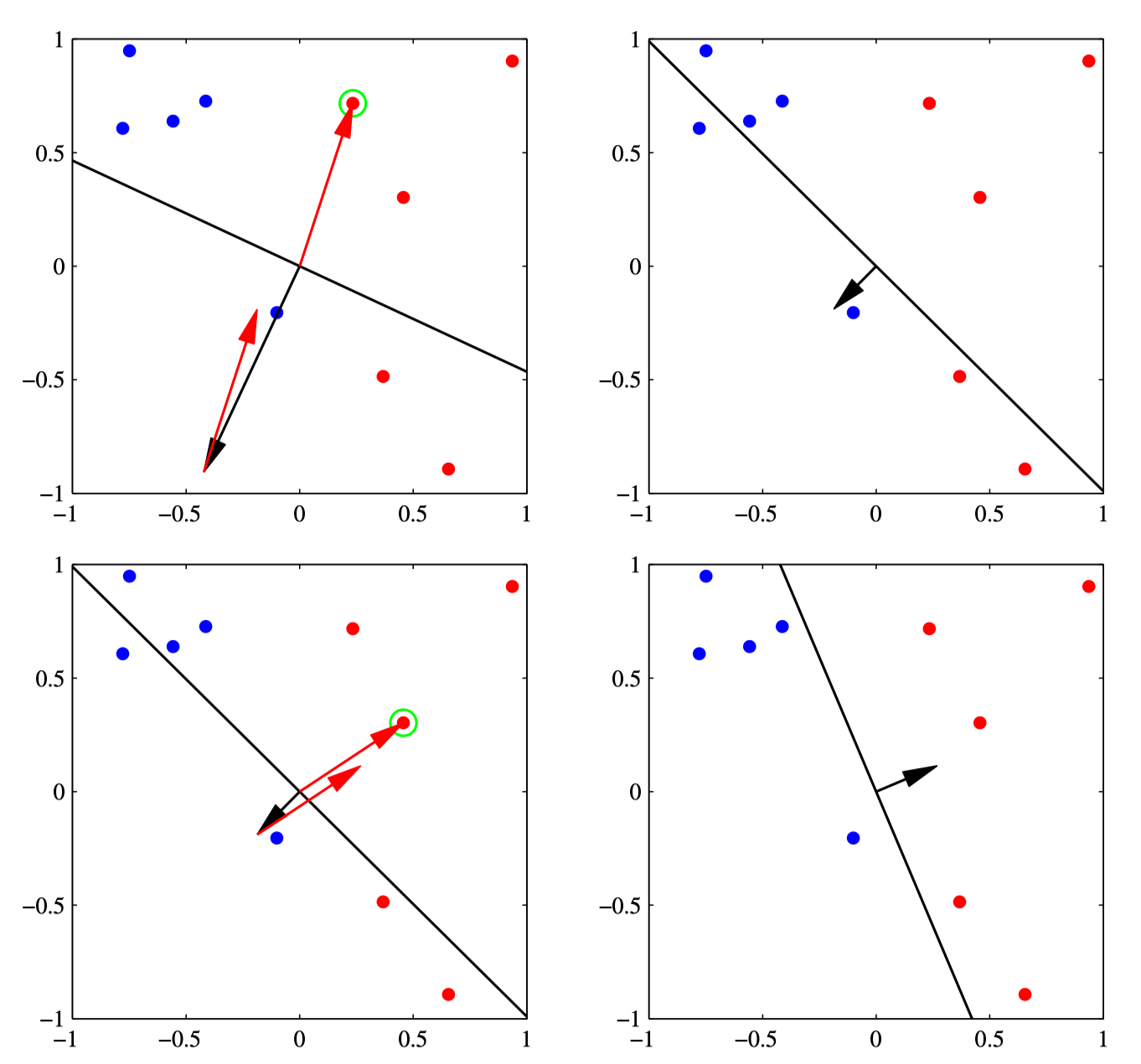
- Top Left: decision boundary (=black line) is initialized, defined by the orthogonal vector (=black arrow). Green point is misclassified with error (=red arrow).
- Top Right: error is added to the parameters to obtain a new decision boundary and new orthogonal vector.
- Bottom Left: Green point is misclassified with error (=red arrow).
- Bottom Right: error is added to the parameters to obtain a new decision boundary and new orthogonal vector. Motivation. We are updating for every single new data that comes in. Doesn’t this mean that the error for other data may go up? No; the math says otherwise: thm. Perceptron Convergence Theorem. If the training data is linearly separable, the perceptron learning algorithm is guaranteeed to find a “exact solution” in finite steps.2