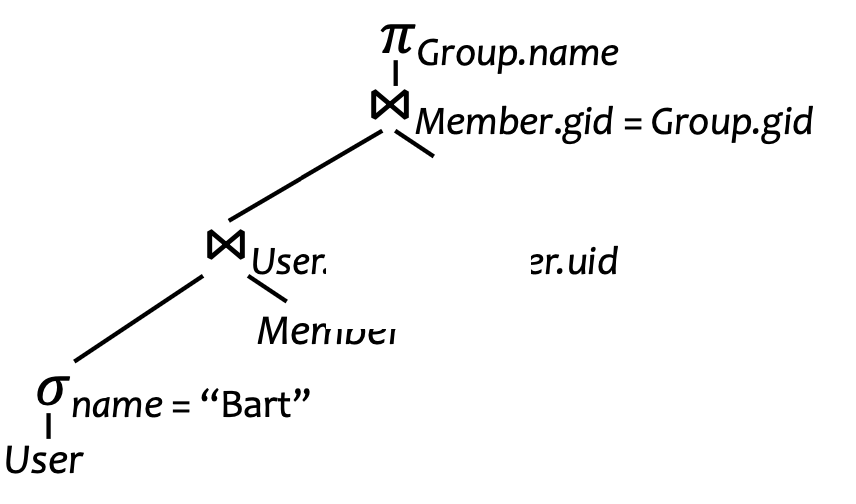
Problem: How to actually process this:
Basic Strategies
- SQL Query rewriting
- Make everything into joins!
- De-correlation: Correlated subqueries are de-correlated using “Magic” de-correlation
- Iterated (=pipelined) algorithm processes
- Process one tuple, up the chain, one at a time
- Will start producing results faster, but may not be fast in total
- Bottom-up Evaluation
- Process the bottommost query, then up one level, etc.
- Use temporary files to store intermediate results
Heuristics-based Optimization
- Idea: estimate size of intermediate results to calculate total operation count
- Cardinality estimation
- Given knowledge:
- Principles:
- Preservation of Value
Selection
- divide by the “selectivity factor”
Conjunction, Disjunction (AND, OR operations)
- Best when are independent columns
Range
- Without values: just say
- With
hi(R.A)andlo(R.B)- & sometimes, highest and lowest is “invalid” → use second highest & lowest
Joins Estimation
Natural Join
- Assumption: containment—every tuple in smaller table joins with bigger table
- ⇒ selectivity factor is the bigger one one
Multi-way Join
- Assumption: preservation of value sets—non-join attribute doesn’t lose values
- ⇒ reduce by selectivity factor for every join
Projection over Join
- Due to assumption of preservation of value sets…
- …when , does not appear in . Therefore we estimate:
Nowadays people use histograms and ML for better estimation
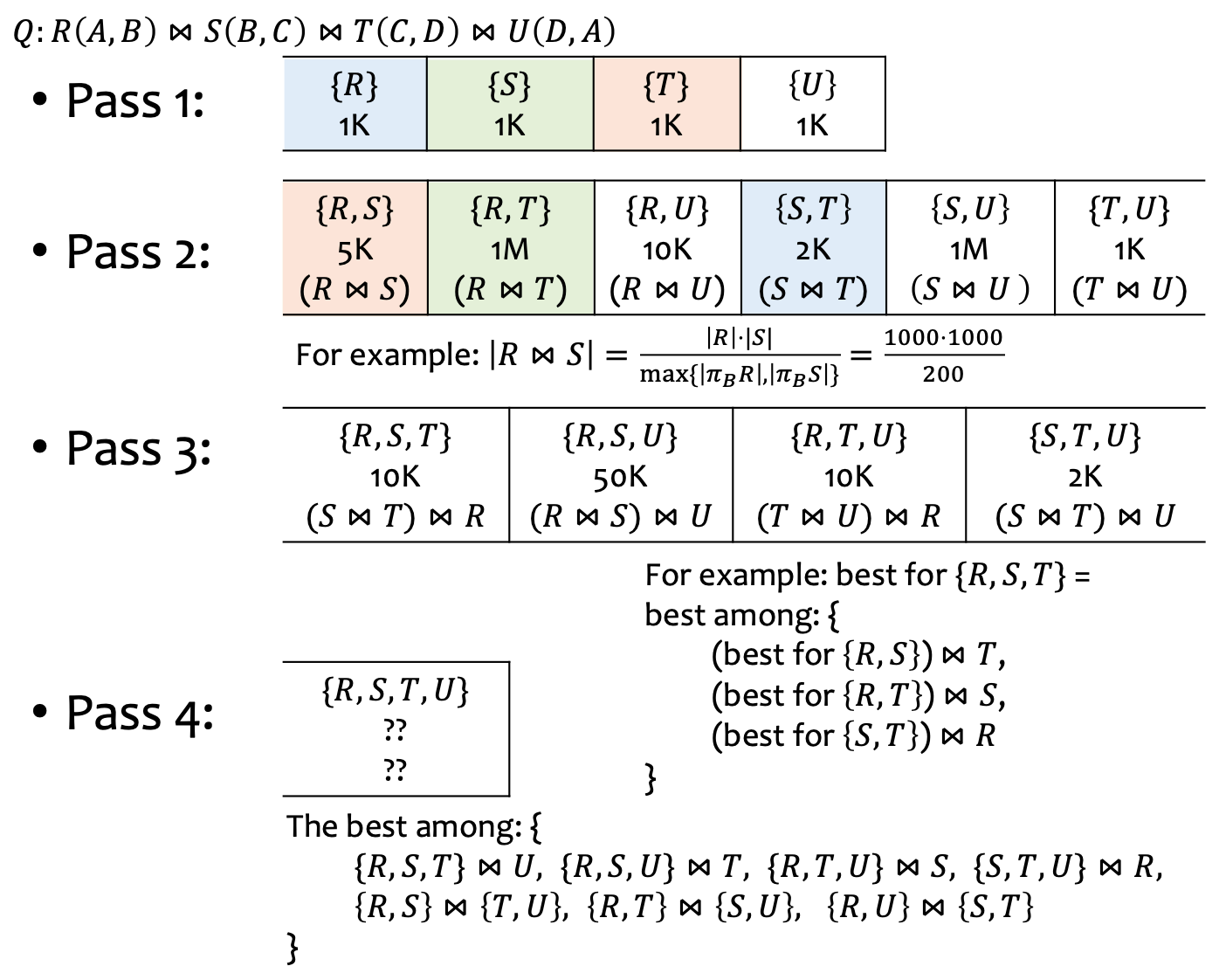
Join Plans
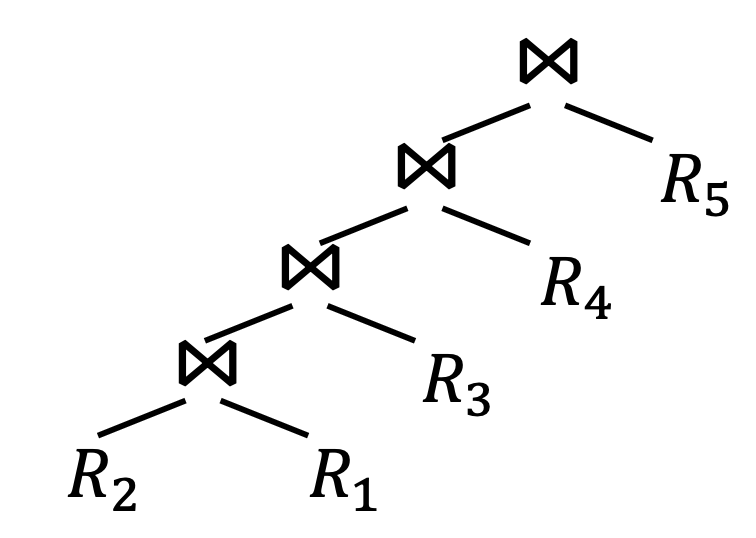
Q. given relations to join, how to join?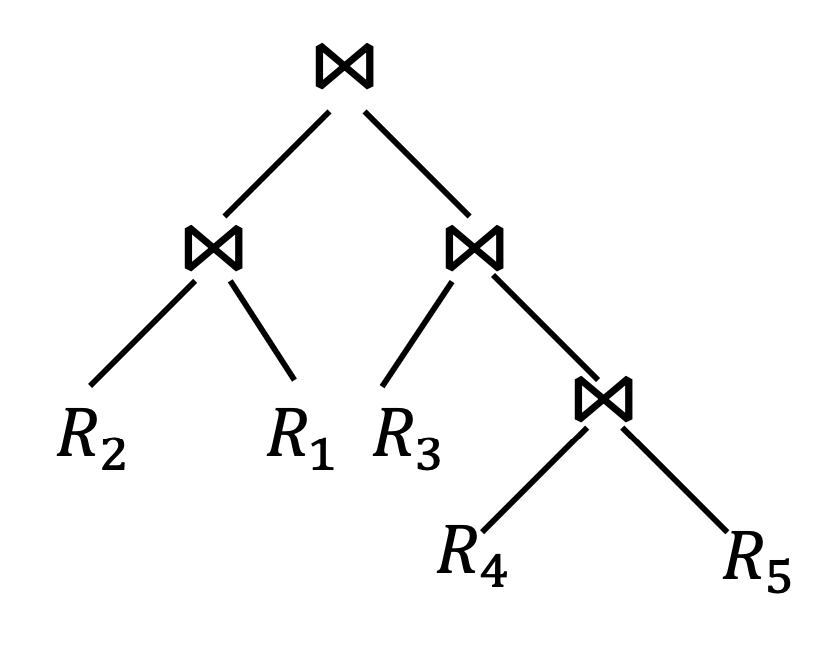
- Brute Force:
- Left-Deep Plan:
- Greedy:
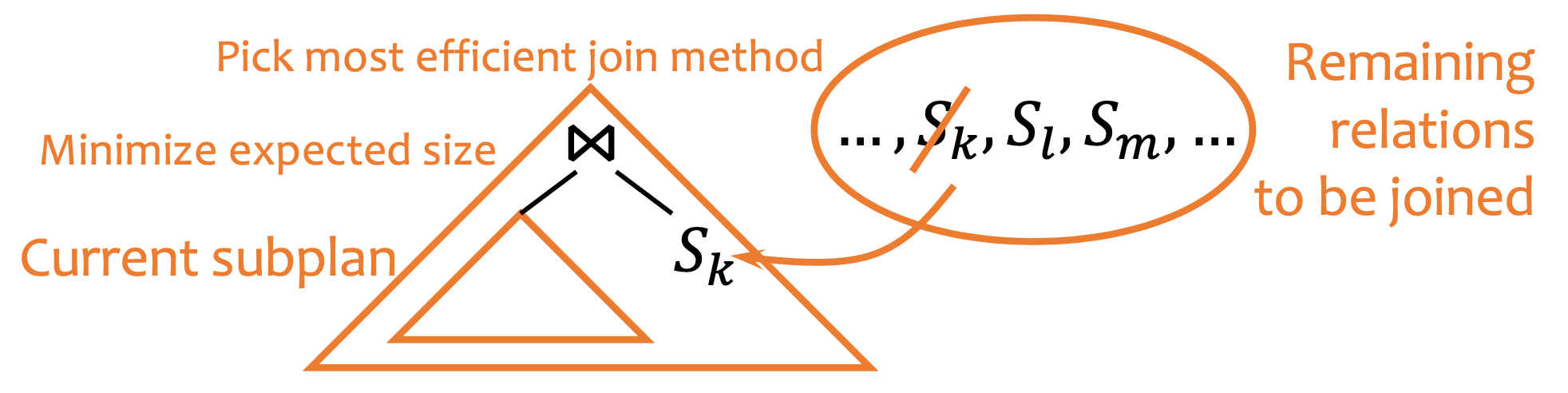
- Dynamic Programming:
- Need to consider: interesting orders (=sorted? deduped? etc.) need to be considered too!