Problem 1
Algorithm is one that assigns every one element to the set with the smaller sum.
(a)
- We first establish that the cost of the algorithm where is the bigger one of .
- let where is the -th processed element by .
- where is the last item added to set
- ! Looking at the first term, we can establish )……(1)
- i.e.
- We know this because is the smaller sum of , and thus the average is bigger than the minimum of the two.
- Then we also establish
- i.e. Sum before sum before and sum after total sum excluding
- ! This implies …….(2)
- & (1) and (2) together shows ……(3)
- ! Looking at the first term, we can establish )……(1)
- We thus show ……(4)
- We know from the lecture (makespan, lemma 1 and 2) that and
- first, because optimal solution cannot be smaller than the total / 2
- second, because optimal solution cannot be smaller than any element
-
- Thus we establish
- We know from the lecture (makespan, lemma 1 and 2) that and
- Thus proven
(b)
- We first investigate the trivial cases when has respectively and elements
- Case
- , thus
- Case
- , thus
- Case
- We then investigate the case when
- As we also know that in the order of assignment by , we can state both that:
- thus ……(1)
- thus ……(2)
- (1)(2) yields
- As we also know that in the order of assignment by , we can state both that:
Problem 2
Code
import csv
from typing import List, Tuple
import time
from math import radians, cos, sin, asin, sqrt
import random
# Function to load data from CSV file
def load_data(riders_filepath) -> List[Tuple[float, float]]:
passengers = []
with open(riders_filepath, 'r') as file:
csv_reader = csv.reader(file)
next(csv_reader, None) # Skip the header
for row in csv_reader:
sourceLat = float(row[1])
sourceLon = float(row[2])
passengers.append((sourceLat, sourceLon))
return passengers
# Assuming the Haversine function is replaced by a simple Euclidean distance for this simulation
def euclidean_distance(point1, point2):
return sqrt((point1[0] - point2[0]) ** 2 + (point1[1] - point2[1]) ** 2)
# 2-approximation algorithm for k-center clustering using Euclidean distance
def k_center_clustering_euclidean(passengers, k, n):
# sample n elements from passengers
passengers = random.sample(passengers, n)
start_time = time.time()
# Choose an arbitrary point as the first center
hubs = [random.choice(passengers)]
for _ in range(1, k):
# Find the next hub as the point farthest from any existing hub
next_hub = max(passengers, key=lambda p: min(euclidean_distance(p, hub) for hub in hubs))
hubs.append(next_hub)
end_time = time.time()
# Assign each point to the closest hub and calculate the cost
assignments = {hub: [] for hub in hubs}
for passenger in passengers:
closest_hub = min(hubs, key=lambda hub: euclidean_distance(passenger, hub))
assignments[closest_hub].append(passenger)
# The cost is the maximum distance of any point to its assigned hub
cost = max(euclidean_distance(passenger, closest_hub)
for closest_hub, passengers in assignments.items() for passenger in passengers)
return hubs, assignments, cost, end_time - start_time
# Example passengers data (replacing the real CSV loading)
passengers = load_data("./passengers.csv")
print(len(passengers))
# Run the algorithm for different values of k and record the results
print("K")
results = {}
for k in range(50,200,10):
hubs, assignments, cost, runtime = k_center_clustering_euclidean(passengers, k, 100)
print(k, ",", runtime)
print("N")
for n in range(1000, 5000, 100):
hubs, assignments, cost, runtime = k_center_clustering_euclidean(passengers, 10, n)
print(n, ",", runtime)
Results
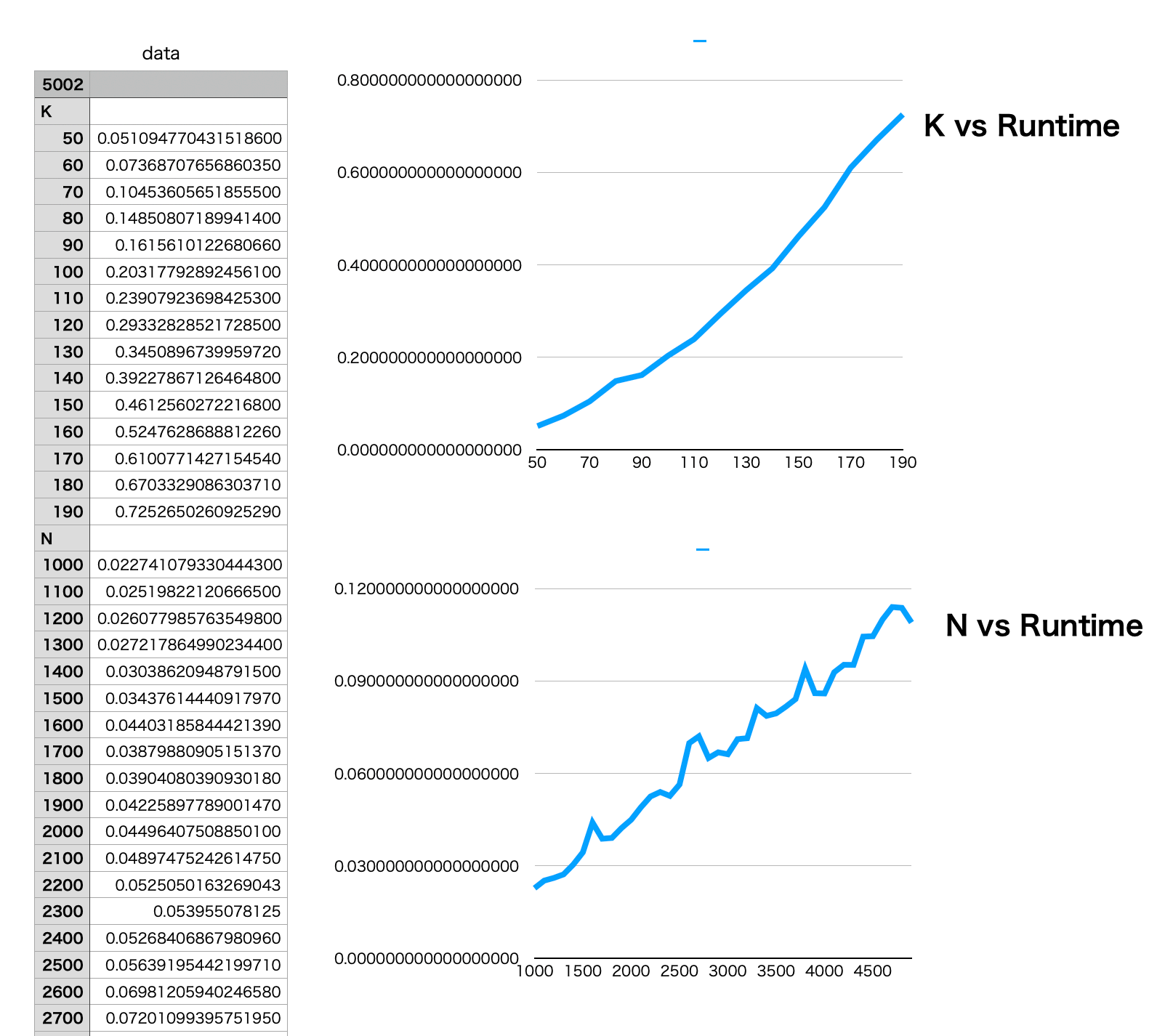
Problem 3
import csv
from typing import List, Tuple
import time
from math import sqrt
import random
import numpy as np
# Function to load data from CSV file
def load_data(riders_filepath) -> List[Tuple[float, float]]:
passengers = []
with open(riders_filepath, 'r') as file:
csv_reader = csv.reader(file)
next(csv_reader, None) # Skip the header
for row in csv_reader:
sourceLat = float(row[1])
sourceLon = float(row[2])
passengers.append((sourceLat, sourceLon))
return passengers
# Euclidean distance function
def euclidean_distance(point1, point2):
return sqrt((point1[0] - point2[0]) ** 2 + (point1[1] - point2[1]) ** 2)
# Function to initialize centroids randomly
def initialize_random(passengers, k):
return random.sample(passengers, k)
# Function to initialize centroids using k-means++
def initialize_kmeans_plusplus(passengers, k):
centroids = [random.choice(passengers)]
# probabilistic initialization
for _ in range(1, k):
distances = [min(euclidean_distance(p, c) for c in centroids) for p in passengers]
probabilities = [d ** 2 for d in distances]
total = sum(probabilities)
probabilities = [p / total for p in probabilities]
next_centroid = random.choices(passengers, weights=probabilities, k=1)[0]
centroids.append(next_centroid)
return centroids
# Assign passengers to the nearest centroid
def assign_passengers(passengers, centroids):
assignments = {}
for passenger in passengers:
closest_centroid = min(centroids, key=lambda centroid: euclidean_distance(passenger, centroid))
if closest_centroid in assignments:
assignments[closest_centroid].append(passenger)
else:
assignments[closest_centroid] = [passenger]
return assignments
# Update centroids based on the mean of assigned points
def update_centroids(assignments):
centroids = []
for points in assignments.values():
centroids.append(tuple(np.mean(points, axis=0)))
return centroids
# Calculate the quality of solution
def calculate_quality(assignments):
total_distance = 0
for centroid, points in assignments.items():
total_distance += sum(euclidean_distance(centroid, p) ** 2 for p in points)
return total_distance / len(assignments)
# k-means algorithm
def k_means(passengers, k, initialize_func):
# Initialize centroids
centroids = initialize_func(passengers, k)
assignments = {}
for _ in range(20): # fixed number of iterations for simplicity
# Assign passengers to the nearest centroid
assignments = assign_passengers(passengers, centroids)
# Update centroids
centroids = update_centroids(assignments)
return centroids, assignments
# Run the k-means algorithm with different initializations
def run_k_means(passengers, k_values):
results = {k: {'random': int, 'k-means++': int} for k in k_values}
for k in k_values:
for _ in range(3): # Repeat the experiment 3 times
temp_results = {init: {'runtime': 0, 'quality': 0} for init in ('random', 'k-means++')}
for init, func in [('random', initialize_random), ('k-means++', initialize_kmeans_plusplus)]:
start_time = time.time()
centroids, assignments = k_means(passengers, k, func)
runtime = time.time() - start_time
quality = calculate_quality(assignments)
temp_results[init]["runtime"] += runtime
temp_results[init]["quality"] += quality
# average the results
results[k]['random'] = (temp_results['random']['runtime'] / 3, temp_results['random']['quality'] / 3)
results[k]['k-means++'] = (temp_results['k-means++']['runtime'] / 3, temp_results['k-means++']['quality'] / 3)
return results
# Example passengers data (replacing the real CSV loading)
# Here we need to load the data from the file provided by the user
# passengers = load_data("/path/to/passengers.csv")
passengers = load_data("./passengers.csv")
print(len(passengers))
# Define k values to test
k_values = [2, 4, 6, 8]
# Run the k-means algorithms and print the results
results = run_k_means(passengers, k_values)
print(results)
Results
| Number of Clusters | Initialization | Runtime | Quality |
|---|---|---|---|
| 2 | random | 0.09817 | 2.26508 |
| 2 | k-means++ | 0.09790 | 2.26508 |
| 4 | random | 0.15675 | 0.77163 |
| 4 | k-means++ | 0.15921 | 0.72164 |
| 6 | random | 0.20530 | 0.39536 |
| 6 | k-means++ | 0.21513 | 0.35047 |
| 8 | random | 0.26586 | 0.23331 |
| 8 | k-means++ | 0.28957 | 0.20059 |