Motivation. Instrumental variables are an advanced way of removing endogenity. Suppose you want to see the effects of police on crime rates. But does crime cause more police to be hired, or does more police cause less crime? Because of this circularity, it’s hard to isolate simply the causality from police to crime rates. So to isolated the exogenous variation in police hiring (i.e. get the pure exogenity), we can use a proxy or instrumental variable: firefighters. Exogenous factors both cause firefighters and police to be hired (policy changes, citizen support) but they don’t cause crime rates to increase.
2-Stage Lease Squares
Instrumental variables are implemented using 2SLS.
- We have the first stage (=reduced form), where we regress the independent variable (police) with instrumental variable (firefighters):
- Then we take the ==police estimator (not the actual data!)== and then regress dependent (crime) against estimated independent (estimated police):
Visualization. 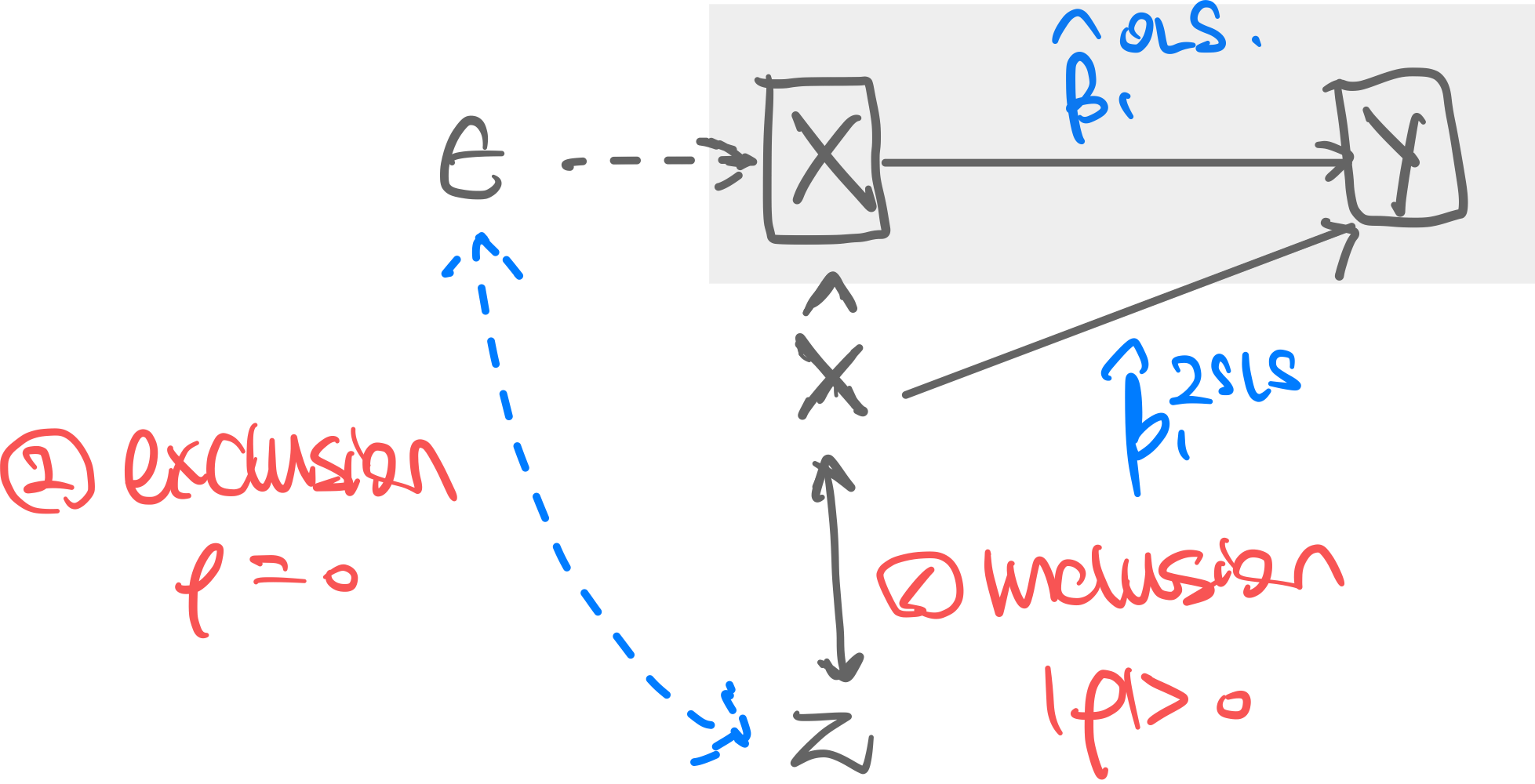
What Are Good Instrumental Variables?
- Inclusion condition: needs to have meaningful influence on
- Satisfied when in the first stage is significant at 1%.
- Exclusion condition: needs to have no infludence on
- in other words, and should not be correlated.
- But this cannot be tested directly because is not observed.
- → thus the exclusion condition is more of a “it’s probably okay” argument
- ! running regression against might seem prudent but actually if is correlated with and with then it will always be significant
- The best we can do is include more controls we assume are inside that correlate with , such that the new with more controls are not correlated to .
Multiple Instruments
Perform the first stage with each instruments :
and then same for the second stage.
Over-identification test tests the exclusion restriction. if you’ve gotten the correct multiple instrumental variables. (Overidentification is a good thing.) If we want to see if and together satisfy the exclusion condition we test:
- First stage just with to get . Then the second stage to get
- First stage just with to get . Then the second stage to get
- If then good!
- ! but if they’re similar this might just mean that both are bad in similar ways…
- And If they’re different, there’s no way of knowing which one is the better one Alternatively, run
and then F-test: . A exclusion-condition compatible IV should not be jointly significant. But this is also inaccurate in the same way described above.
Comparison with Ordinary Least Squares
We should use 2SLS instead of OLS when we know that is very much endogenous, and we have found a good IV, that satisfies the inclusion and exclusion conditions. To test if is endogenous enough for 2SLS to be useful, we use the following: def. Durbin-Wu-Hausman Test of ’s endogenity. Observe first the fact that assuming is exogenous:
- if is exogenous:
- i.e. already, so why use IV or 2SLS?
- if is endogenous:
- i.e. so we must use IV or 2SLS! The test has null hypothesis . If we reject the null, then we should use 2SLS.
Bias in 2SLS
- def. Quazi-instruments are instruments where there exists some (small) (Usually okay, see below)
- def. Weak Instruments are instruments where there exists some . (Usually bad, see below) It’s sometimes okay to have some correlation between and , but having correlation between and is pretty bad. To see why, observe the 2SLS bias of
Compare this to vanilla OLS (for Consistency ):
This implies
- When it has a strong first stage relationship (= is small) the 2SLS’s
- & If then 2SLS has less bias than vanilla OLS even if
- ! If then 2SLS amplified any small correlation and easily becomes worse than vanilla OLS
Rule of Thumb for determining weak instruments
Use 2SLS with instrument when in the first stage regression the test
i.e. an F-test, .
- Even when , since the above equations are for , when is small bias still exists (in the same direction as OLS).
- This bias will eventually go away in bigger (or, of , go the opposite way!)
Precision of 2SLS
Recall multivariate OLS variance of coefficients is:
The 2SLS variance of coefficient is:
The differences are:
- (=second stage regression variance) may be larger because has been purged
- This simplies that explainatory power in the observed that were correlated with is purged (=thus total reduced)
- , not because we use estimates (see above) not actual data during regression
- is probably smaller because we purged -related variance.
- ! is the R-squared from the new regression
- This regression determines how much does $X_{2}$, not $Z$, determines $\hat{X_{1}}$.
- $R^{2}$ in this regression thus measures the collinearity of $\hat{X_{1}}$ and $X_{2}$ (=controls)
- btw, $R^{2}$ in the second regression doesn't mean shit.
- The lower the explanatory power of $Z$ on $\hat{X_{1}}$, the higher this value is, and the higher the variance of the 2SLS coefficient is.