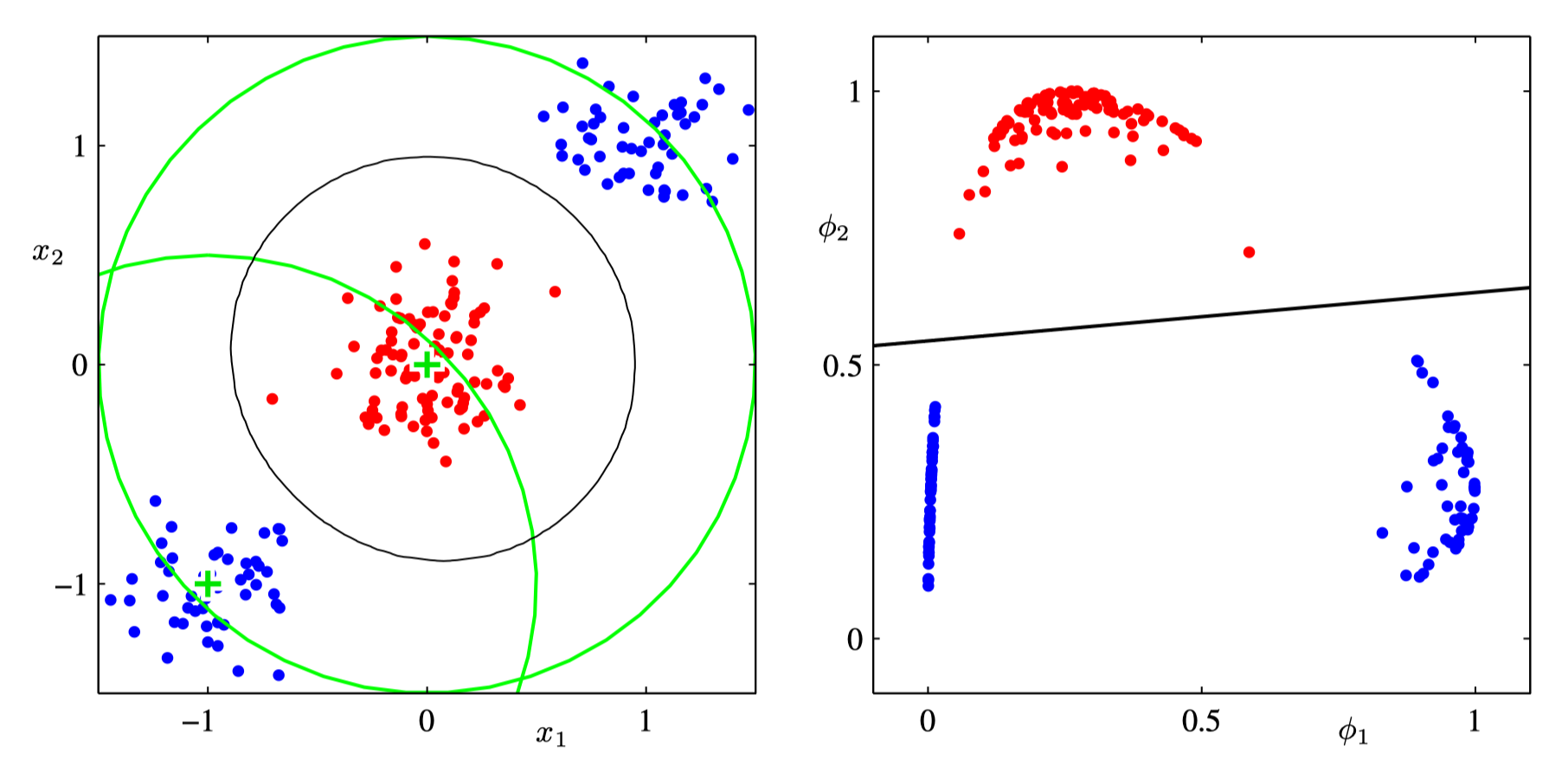
Motivation. Suppose there was a transformation from the input space into a “feature space”, where all datapoints where nicely linearly dividable, like the following:
 Then, let’s run a classifier using a logistic model (=Softmax and Sigmoid) We will:
Then, let’s run a classifier using a logistic model (=Softmax and Sigmoid) We will:
- Construct a likelihood of a single datapoint being classified correctly
- Construct a likelihood of all datapoints classified correctly
- Use the negative of log-likelihood as a error function to minimize
- Calculate the gradient of that error function The input data is mapped into a output classification like this:
- is the dimension of the input space
- the feature space (how many features there are).
- is the number of classes.
- Note that the output is a one-hot encoding.
- We have a weight vector for each feature .
- We are given datapoints
- is in this case also a vector because the target is one-hot encoded as well
Visualization. The following visualization of matrix-vector multiplication may clarify this process:

- is in this case also a vector because the target is one-hot encoded as well
Visualization. The following visualization of matrix-vector multiplication may clarify this process:
Constructing the Likelihood Function
We start with which is the density given one data point, for a single class, . We omit the for clarity. Let’s omnit subscript labels too. Then consider the density that a single data point, has the correct classification (one-hot encoding):
Raising to the power simply has the effect of only obtaining for the class where . The rest of the elements of the vector are ignored. And finally that all datapoints have the correct classification:
Error Function
The error function is the negative-log of the likelihood. Simply:
Coincidentally this error function is the cross-entropy between “distributions” and . This is just a coincidence and abuse of notation to call it cross-entropy. Moving on; now, consider optimizing for a single weight class, . We have:
requires the chain rule. Observing the mapping from the input data to the output probabilities, let’s consider the gradient for just one of the weights, for class
We calculate all three of these:
-1.