Section: Pushdown Automata
def. a Context-Free Grammar (CFG) is a grammar whose production rules consist of:
…where is a variable, and is a string of variables and terminals.
CFGs can check for syntactically correct programs
- Simple Grammar: a CFG where any pair of appear in no more than one rule.
- Ambiguous Grammar: there exists a string in the language that has more than one derivation.
def. a Parse Tree [=Derivation Tree] shows the derivation steps of a single string from a start symbol according to the rules of a grammar.
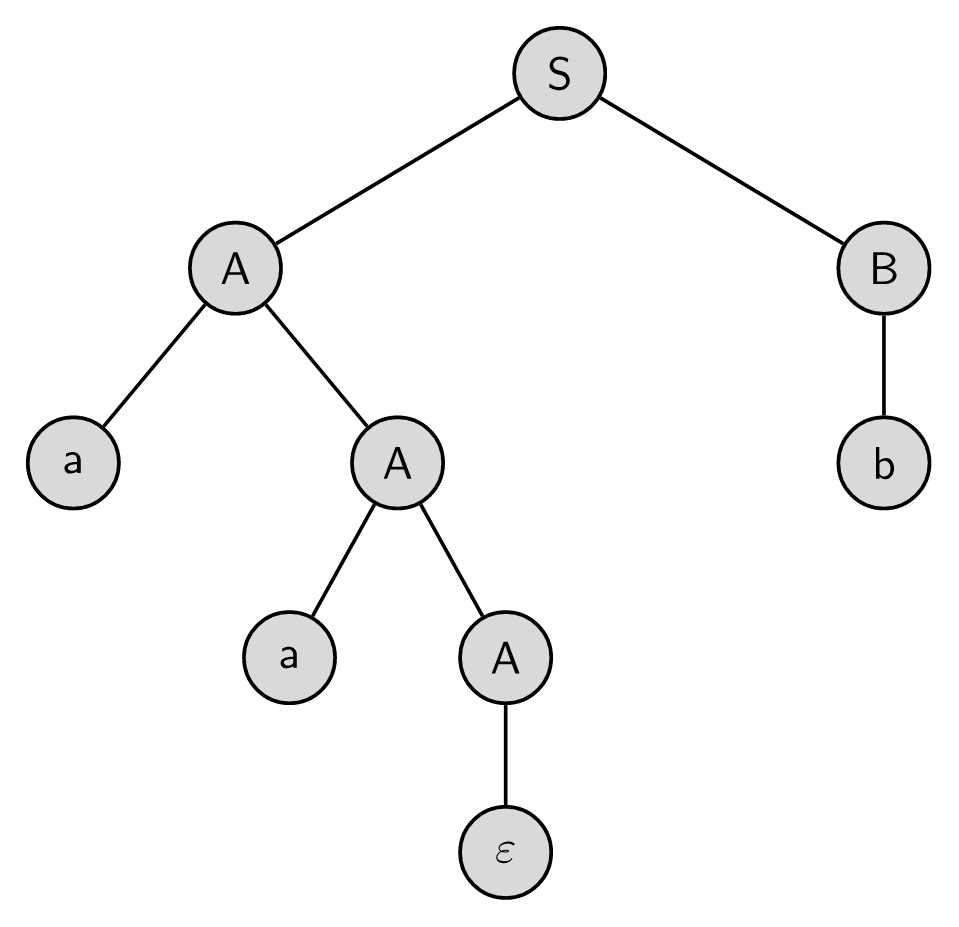
- The leaves of the tree read right-to-left is the yield of the tree—in this case, is the yield.
- The yield should not contain the s. (obviously)
def. Leftmost Derivation. Replace the leftmost variable in every step.
def. Rightmost Derivation. Replace the rightmost variable in every step.
Normal Forms
def. Chomsky Normal Form. A CFG is in CNF iff all rules are in the form:
- thm. All CFGs can be expressed in CNF1 def. Greibach Normal Form. A CFG is in GNF iff all rules are in the form:
thm. Determinability. If the CFG doesn’t contain rules of the form or , then we can determine for all if it is in the language of the CFG.
thm. a Context-Free Grammar is equivalent to an NPDA.
NPDA → CFG
alg. Given NPDA, you can define an equivalent CFG in the following steps:
- For any transitions that pop/push more than one variable onto the stack:
- Use a new state to split out the transition, so that one transition only push/pops one variable onto the stack
- Then, for each transition arc:
- If the transition arc is a pop arc that pops off the stack, i.e.: from state to is in the form , then construct a production rule for the grammar as:
- If the transition arc is a push arc that pushes onto the stack i.e.: from state to is in the form then construct a production rule for the grammar as: , where is every possible combination of states in the PDA(!)
- Finally, of all the rules generated, if any variables on the right side of the arc don’t appear on the left side, that rule is useless.
CFG → NPDA
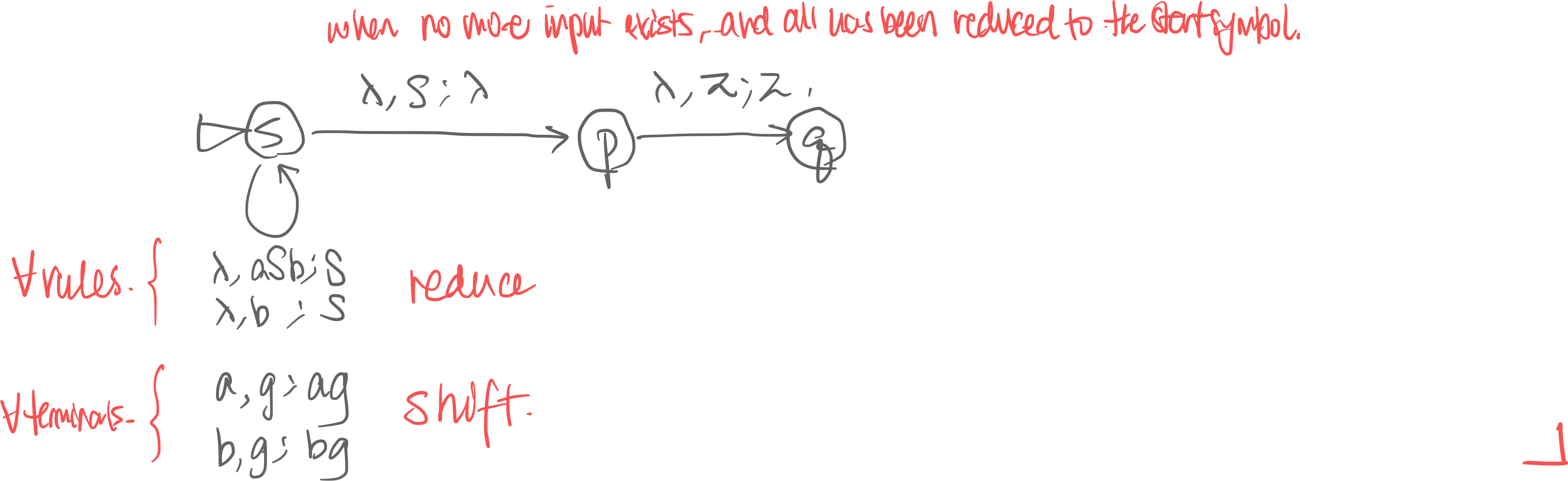
alg. Given a CFG, you can build an LL-NPDA in the following steps. This is a top-down design:
- There are 3 total states in the NPDA: 0, 1, 2
- Move from state 0 to state 1 by adding the start variable S onto the stack
- The middle state has loops for every rule of the CFG. Pop off the LHS, add the RHS to stack while processing any beginning terminals
- Move from state 1 to final state 2 in a -transition
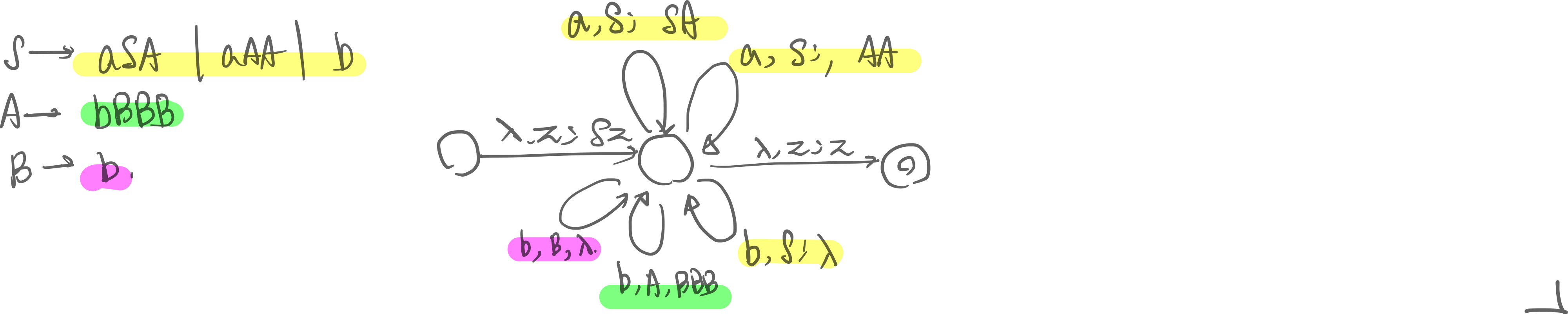
alg. Given CFG, you can build an LR-NPDA in the following steps. This is a bottom-up design:
- There are 3 total states in the NPDA: 0, 1, 2
- State 0 has loops for:
- …every rule of the grammar. Each rule will pop the RHS and push the LHS of the rule
- …every terminal of the grammar. Each terminal will be pushed onto the stack while reading that terminal.